Devoxx Poland is an annual Java conference held in Krakow Congress Centre with over 2000 attendees. This year the organizers tried their best to improve the conference in all areas. Like last year, this year was no exception – what awaited us there were great talks, workshops and valuable learning experiences! Within this blog, we will give you a small insight as to what we’ve learned there and our personal experience from the conference.

An opening presentation held by Brian Christian, the co-author of the book. It showed us how algorithms can influence our day to day lives, like searching for an apartment, finding a free parking spot or even love of your life!
Imagine that you are trying to buy an apartment, however, the market is always changing and if you do not make an immediate decision you could lose the best apartment you could find. However, if you postpone your decision and choose to look for other options you could lose the best offer you could find. This problem is often referred to as an optimal stopping problem. The key takeaway is that 37% is the answer where you should make your decision and up until then not make any. For example, if you want to find an apartment in 5 months the 37% of that time should be spent on just looking and calibrating your choice. After that period of time, you should make a decision that fits you the best and is better than previous ones.
The presentation went more in depth, talking about the situation where you actually can go back to your previous decision or other modifications to this problem. The book itself contains more examples of our day to day activities which could be modified by basic algorithms and free our mind of some important decisions.
„GraphQL – The Next API Language “. It is basically an alternative to REST web service, developed by Facebook and first used in 2015. It enables you to specify exactly which data you want from the endpoint. Instead of multiple endpoints with fixed data models, GraphQL server only exposes one endpoint and respond just with data that the client asked for. For example, in REST when you use GET /customers/123 you will get from the server all data in your model of the customer. This is a problem in some cases, especially when you want to minimize data transfer between client and server. Let’s say, you want to know only the name and age of the customer. Then you could use GET /customers/123?fields=name,age or create different endpoint method which uses a different model or some other solution. That wouldn’t be that bad if this is the only case when you do not want to retrieve whole customer data, but you might want to have many other cases for which you need different sets of data to be retrieved from the server.
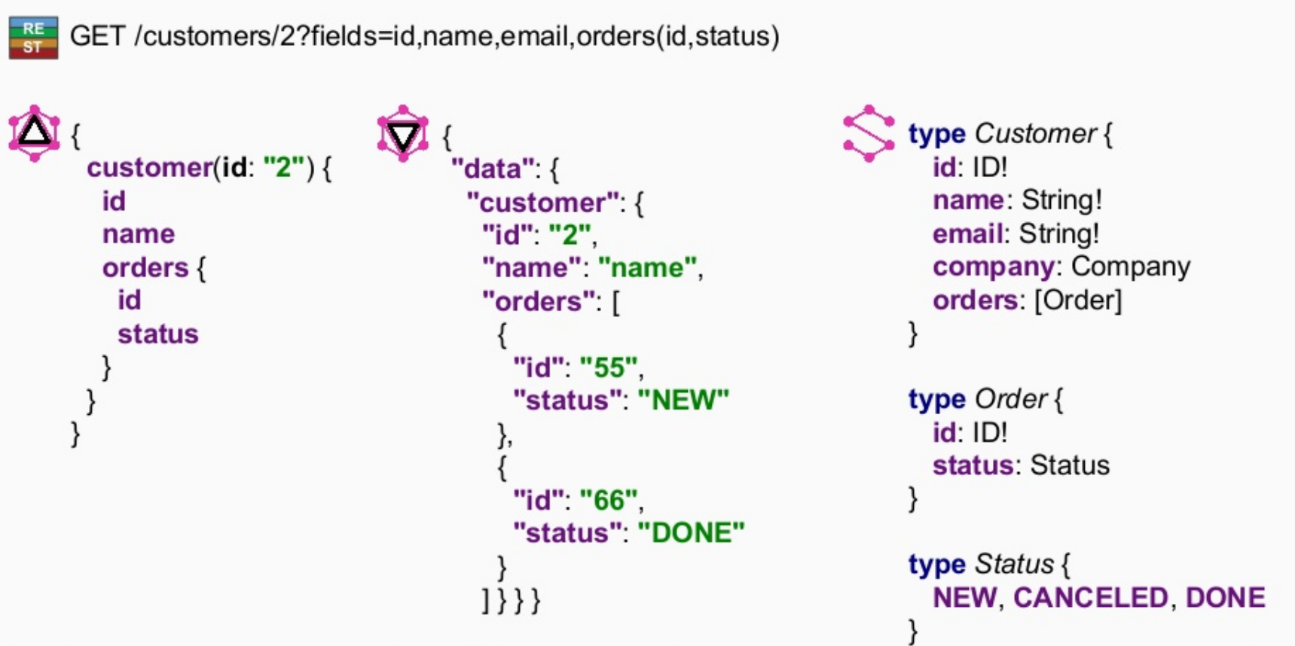
On this example, you can see GraphQL request on the left and response in the middle. On the right, there is a schema definition. Supported types or model can be defined by the code, or by the schema. Schema definition is, for now, better as it is easier to maintain and to understand. GraphQL supports filtering, sorting, pagination and testing frameworks as a spook or groovy are also usable to test GraphQL applications. GraphQL is a nice alternative to REST but it can be used together with REST.
It returns exactly what you ask for and is easily testable and recently, some nice tooling provides even easier handling with GraphQL. You do not need to different endpoints for a different type of clients (PC, Android, IOS,) because clients can ask for the data that they actually need, and only those data will be returned. But it is not good for everything.
You can basically imagine GraphQL as a “middle man” that is filtering server response before it transfers data to the client. Price for less transferred data is performance overhead needed on the server side.
Bitcoin is already a well-known word for many of the people. But not everybody knows about the blockchain. Blockchain is actually the technology that allowed the creation of bitcoin and many other cryptocurrencies. The first concept was described in 1991 by Stuart Haber and W. Scott Stornetta. They wanted to implement a system where document timestamps could not be tampered with. The first blockchain was conceptualized by a person (or group of people) known as Satoshi Nakamoto in 2008. Nakamoto improved the design in an important way using a Hashcash – like a method to add blocks to the chain without requiring them to be signed by a trusted party.
Every blockchain starts with the first block which is called genesis block.
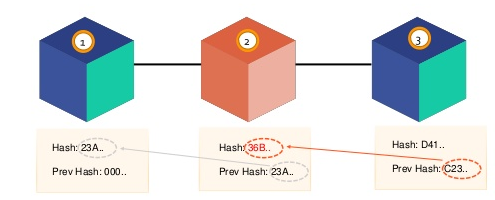
One block typically consists of five parts:
Hash is always a unique sequence which is created based on some input. In this case, data are mixed with the nonce and the output is the hash sequence. If we want to add a new block to the chain, we need to have a valid hash. When creating a blockchain, we can decide the rules. For example, we can tell that valid hash must start with the sequence “123”. Then each new block must have a hash that starts with this number. As mentioned, the hash is created from a mix of data and nonce and is always unique. So how do we create a hash that will start with sequence 123? Here is the example:
| Data | Nonce | Hash |
| Transaction from 1 to 2 | 1 | 1sd48asda5 |
| Transaction from 1 to 2 | 2 | 178ds8wa9 |
| … | … | … |
| Transaction from 1 to 2 | 489 | 123sad8wa |
Basically, we must find search for the nonce which will result together with data in a valid hash. This is a time-consuming operation, as we need to calculate the hash for each nonce again and again until we find the correct one. In this example, it would be 489 calculations. But once we find correct nonce, everybody can verify and proof only one step, that this nonce and data will result in a valid hash. When the majority of the network verify result, this block will be added to the blockchain as a new block.
This is called proof of work concept.
This concept is the basic concept of blockchain and by adjusting rules of hash complexity we can decide how difficult it is to create a valid block. For example, for bitcoin, it is about 10 minutes and for ethereum, it is about 15 seconds.
Blockchain can be, and is used for more than the sending and receiving money. Each blockchain defines its blocks, so also the size of the data part of the block can be different. For example, ethereum block can contain simple programming code in the data part. This allows the creation of “smart contacts”. This opens many possibilities how we can use blockchain as programmers.
There are also some negatives of the blockchain. One of those is the power consumption.
Only bitcoin mining uses as much electric power as whole Ireland. And there are many other implementations of the blockchain. If one group control more than 50% of the blockchain network, it can temper the blockchain, because a new block is accepted only when the majority of the users in the network approves this new block.
There is many more to this topic, for example, system how actual coins are distributed over the network, why do coins have some monetary value and many others so if you are interested in, be sure to check it out.
GraalVM offers a comprehensive ecosystem supporting a large set of languages (Java and other JVM-based languages, JavaScript, Ruby, Python, R, and C/C++ and other LLVM-based languages) and running them in different deployment scenarios (OpenJDK, Node.js, MySQL, Oracle Database, or standalone).
The Graal name in the GraalVM comes from the Graal compiler. Current known compilers in Java are C1 and C2 ( sometimes called “client” and “server” ) and a modern Java installation uses both JIT compilers during normal program execution. Frequently called methods are interpreted using C1 and after even bigger load the method will be recompiled using C2. This is the strategy known as “Tiered Compilation”. C2, in general, is very successful and can deliver major speed improvements to the existing code, however, have not received too many upgrades in recent past and is believed to be reaching the end of its life, as upcoming changes will be only marginal.
In order to use Graal we have to use Java 9 as it uses JVMCI Java-Level JVM Compiler Interface. It allows new compilers to be plugged in. The switches to enable the new JIT compiler to be used are:
-XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:+UseJVMCICompiler
This means that there are three different ways that we could run a simple program – either with the regular tiered compilers, or with the JVMCI version of Graal on Java 10, and finally with GraalVM itself.
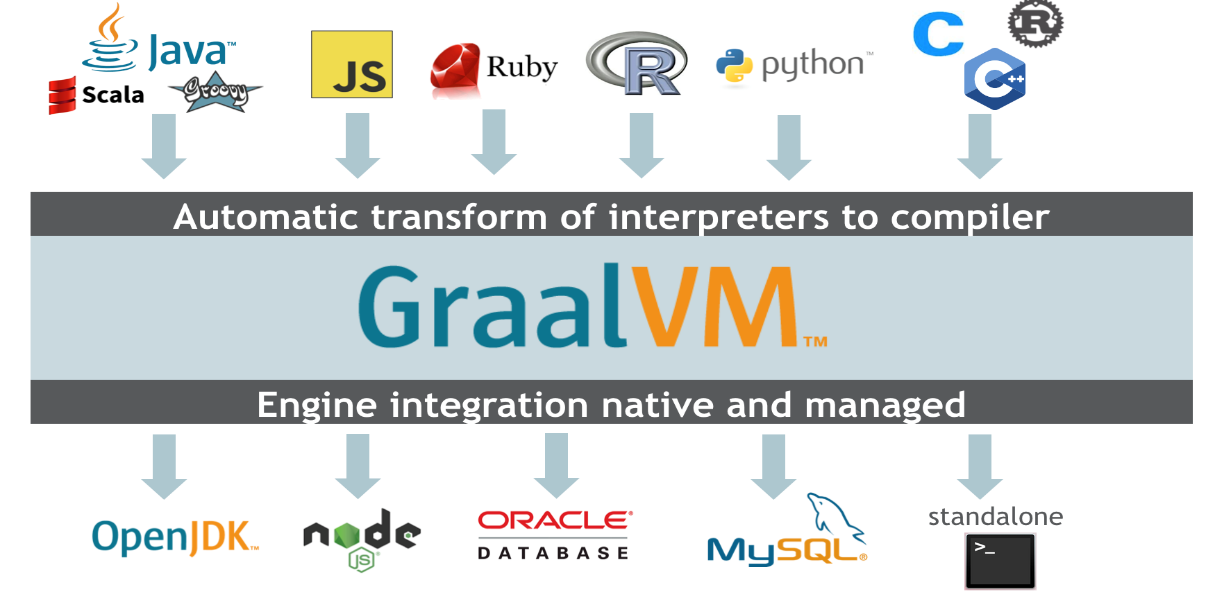
For existing Java applications, GraalVM can provide benefits by running them faster, providing extensibility via scripting languages, or creating ahead-of-time compiled native images. GraalVM can run in the context of OpenJDK to make Java applications run faster with a new just-in-time compilation technology. Better inlining and more aggressive speculative optimizations can lead to additional benefits for complex long-running applications.
Often developers have to make uncomfortable compromises that require them to rewrite their software in other languages. GraalVM allows you to write polyglot applications with a seamless way to pass values from one language to another.
In order to provide foreign polyglot values meaning in the languages, we have developed the so-called polyglot interoperability protocol. This interoperability protocol consists of a set of standardized messages that every Graal language implements and uses for foreign polyglot values.
In this code:
Together with cool technical topics that were presented during these three days, there were also some nice geek/methodology/culture topics. For example in the presentation “How to introduce 3 years old to the world of computers”, there were presented several options you have, in case you want to create an interest in “programming” for young children.
Other presentation with the name “How to impress your boss and your customer in a modern software development company”, helped us to understand what skills, behaviors and what mindset is the most valuable in a software developer from the perspective of management and customer and which drives them nuts.
In presentation “HabitatOS and Bioastronautics research at LunAres habitat” we were introduced to an interesting project of a simulated space base and a research laboratory located in Pila, Poland.
Apart from talks, there are a lot of other activities to interact with people and most importantly, to relax. Pinball machine corner, ice cream truck or various company stands allowed us to meet new people and enjoy our stay there.

Blog entry allows us only this much to share our experience with you, thus here are some key recommendations we found interesting and which could help you as well.
Compared to the GeeCon conference we could say that both were very good in terms of content and presentations. Great speakers and multiple simultaneous presentations so that you can always choose the one that you like. But as for the atmosphere and organization, Devoxx Poland 2018 was much better with more things to do in between the presentations.
Devoxx conference taught us much and gave us a lot to think about. If we would have to summarize it in one sentence, we would say that apart from the learning aspect it gives energy and creative ideas to everyone, which is the basis as to why we do love our jobs as developers. We hope we have inspired you to join us next year, as personal experience is always better. See you there!
Java Developer
Jozef pracuje ako Java Developer v žilinskej pobočke Davinci. Jave a objektovému programovaniu sa venuje už niekoľko rokov, pričom získal znalosti z technológií ako Gwt, Hibernate, Spring, Maven či JSF. Programovanie samo o sebe je jeho najväčšou záľubou vďaka tomu, že ponúka veľký priestor kreativite riešenia problémov. Aj napriek nábehu na workoholika je stále dobre naladený. Vo voľnom čase si dobíja baterky spoločenským tancom, športom či stolovými hrami.
Java Developer
Majo v Davinci software pracuje na pozícii Java Developer. K tejto práci sa dostal popri štúdiu na Žilinskej univerzite, odbor počítačové inžinierstvo. Od prvého kontaktu s Javou však vedel, že budú kamaráti. V minulosti sa tiež venoval vývoju jednoduchých Android aplikácií. Majov život vo veľkej miere ovplyvnilo Japonsko, ktoré je s prírodou jeho najväčšia záľuba. Prácu v IT vyvažuje množstvom záľub ako sú alternatívne médiá, bicyklovanie, filmy, fotenie, hry, hudba, knihy, ľadové medvede, technológie a varenie.
Do you see yourself working with us? Check out our vacancies. Is your ideal vacancy not in the list? Please send an open application. We are interested in new talents, both young and experienced.
Join us